Mathematics of Hidden Markov Models: filtering, smoothing, and inference via Expectation-Maximization.
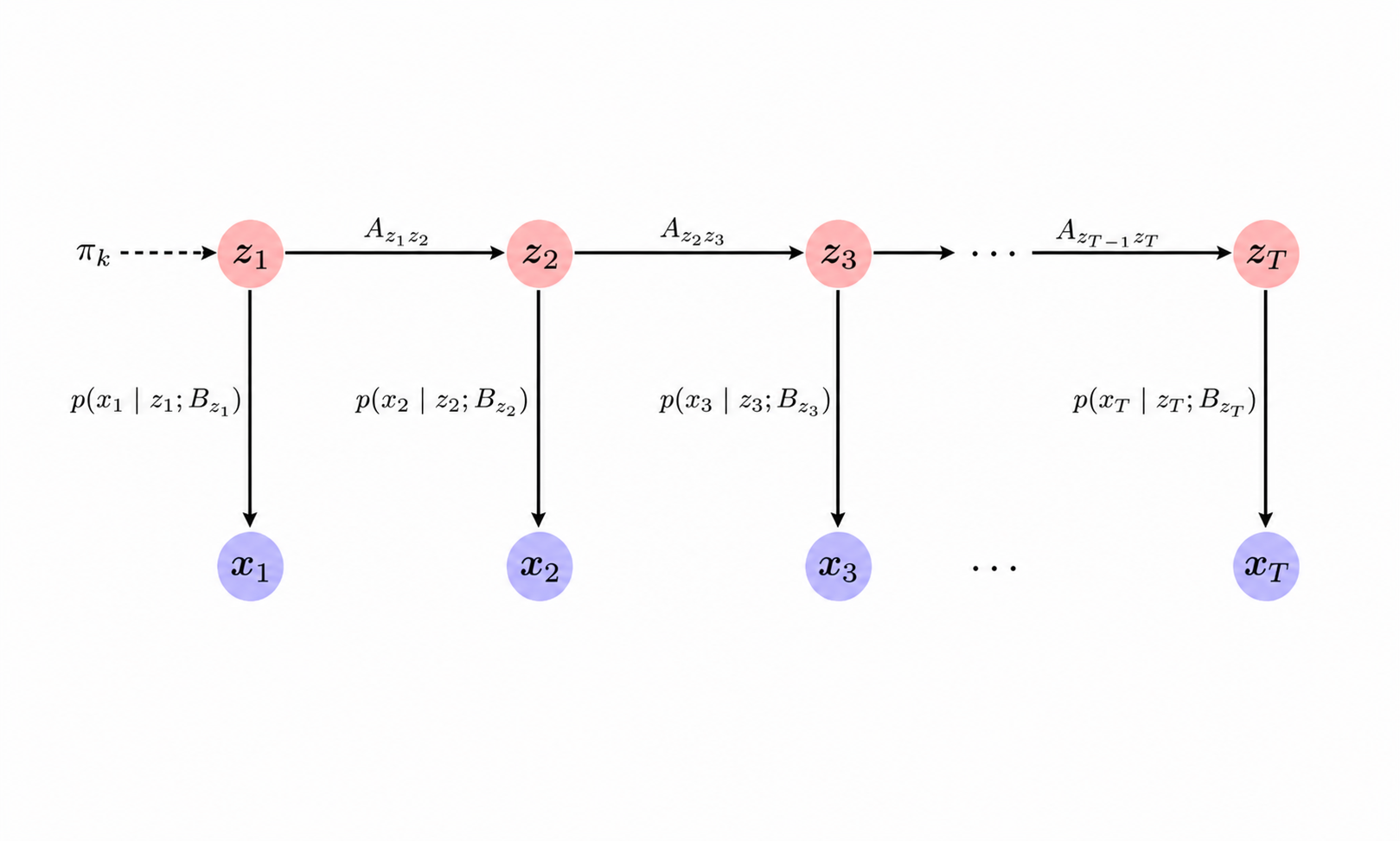
Model Definition A Hidden Markov Model (HMM) consists of a sequence of hidden states z 1 : T z_{1:T} z 1 : T z t ∈ { 1 , … , K } z_t \in \{1,\dots,K\} z t ∈ { 1 , … , K } x t x_t x t
p ( z 1 : T , x 1 : T ) = p ( z 1 ) ∏ t = 2 T p ( z t ∣ z t − 1 ) ∏ t = 1 T p ( x t ∣ z t ) (1) p(z_{1:T}, x_{1:T}) = p(z_{1}) \prod_{t=2}^{T} p(z_{t} \mid z_{t-1}) \prod_{t=1}^{T} p(x_{t} \mid z_{t}) \tag{1} p ( z 1 : T , x 1 : T ) = p ( z 1 ) t = 2 ∏ T p ( z t ∣ z t − 1 ) t = 1 ∏ T p ( x t ∣ z t ) ( 1 ) The factorization encodes two key conditional independence assumptions: (1) the evolution of latent states is 1-Markov, and (2) each observation depends only on the contemporaneous latent state.
Figure 1: Graphical structure of a Hidden Markov Model. Latent states z 1 : T z_{1:T} z 1 : T x t x_t x t z t z_t z t
Inference Since only x 1 : T x_{1:T} x 1 : T filtering p ( z t = k ∣ x 1 : t ) p(z_t=k \mid x_{1:t}) p ( z t = k ∣ x 1 : t ) smoothing p ( z t = k ∣ x 1 : T ) p(z_{t}=k \mid x_{1:T}) p ( z t = k ∣ x 1 : T ) z t z_t z t
Filtering: Inferring Current Latent State Filtering is the task of computing the posterior p ( z t = k ∣ x 1 : t ) p(z_t=k \mid x_{1:t}) p ( z t = k ∣ x 1 : t ) t t t
p ( z t = k ∣ x 1 : t ) = p ( x 1 : t , z t = k ) p ( x 1 : t ) (2) p(z_{t}=k \mid x_{1:t}) = \frac{p(x_{1:t}, z_{t}=k)}{p(x_{1:t})} \tag{2} p ( z t = k ∣ x 1 : t ) = p ( x 1 : t ) p ( x 1 : t , z t = k ) ( 2 ) it suffices to track the numerator p ( x 1 : t , z t = k ) p(x_{1:t}, z_{t}=k) p ( x 1 : t , z t = k ) x t ⊥ ( z t − 1 , x 1 : t − 1 ) ∣ z t x_{t} \perp (z_{t-1}, x_{1:t-1}) \mid z_{t} x t ⊥ ( z t − 1 , x 1 : t − 1 ) ∣ z t z t ⊥ x 1 : t − 1 ∣ z t − 1 z_{t} \perp x_{1:t-1} \mid z_{t-1} z t ⊥ x 1 : t − 1 ∣ z t − 1
p ( x 1 : t , z t = k ) = ∑ j = 1 K p ( z t = k , z t − 1 = j , x 1 : t ) = ∑ j = 1 K p ( x t ∣ z t = k ) p ( z t = k ∣ z t − 1 = j ) p ( z t − 1 = j , x 1 : t − 1 ) = p ( x t ∣ z t = k ) ∑ j = 1 K p ( z t = k ∣ z t − 1 = j ) p ( z t − 1 = j , x 1 : t − 1 ) \begin{align*}
p(x_{1:t}, z_{t}=k) &= \sum_{j=1}^{K} p(z_{t}=k, z_{t-1}=j, x_{1:t}) \\
&= \sum_{j=1}^{K} p(x_{t} \mid z_{t}=k)\, p(z_{t}=k \mid z_{t-1}=j)\, p(z_{t-1}=j, x_{1:t-1}) \\
&= p(x_{t} \mid z_{t}=k) \sum_{j=1}^{K} p(z_{t}=k \mid z_{t-1}=j)\, p(z_{t-1}=j, x_{1:t-1})
\end{align*} p ( x 1 : t , z t = k ) = j = 1 ∑ K p ( z t = k , z t − 1 = j , x 1 : t ) = j = 1 ∑ K p ( x t ∣ z t = k ) p ( z t = k ∣ z t − 1 = j ) p ( z t − 1 = j , x 1 : t − 1 ) = p ( x t ∣ z t = k ) j = 1 ∑ K p ( z t = k ∣ z t − 1 = j ) p ( z t − 1 = j , x 1 : t − 1 )
Definition (Forward variable). Define α t ( k ) ≡ p ( x 1 : t , z t = k ) \alpha_t(k) \equiv p(x_{1:t}, z_t=k) α t ( k ) ≡ p ( x 1 : t , z t = k ) t ≥ 1 t \geq 1 t ≥ 1
Proposition (Forward recursion). The forward variables satisfy, for t ≥ 2 t \geq 2 t ≥ 2
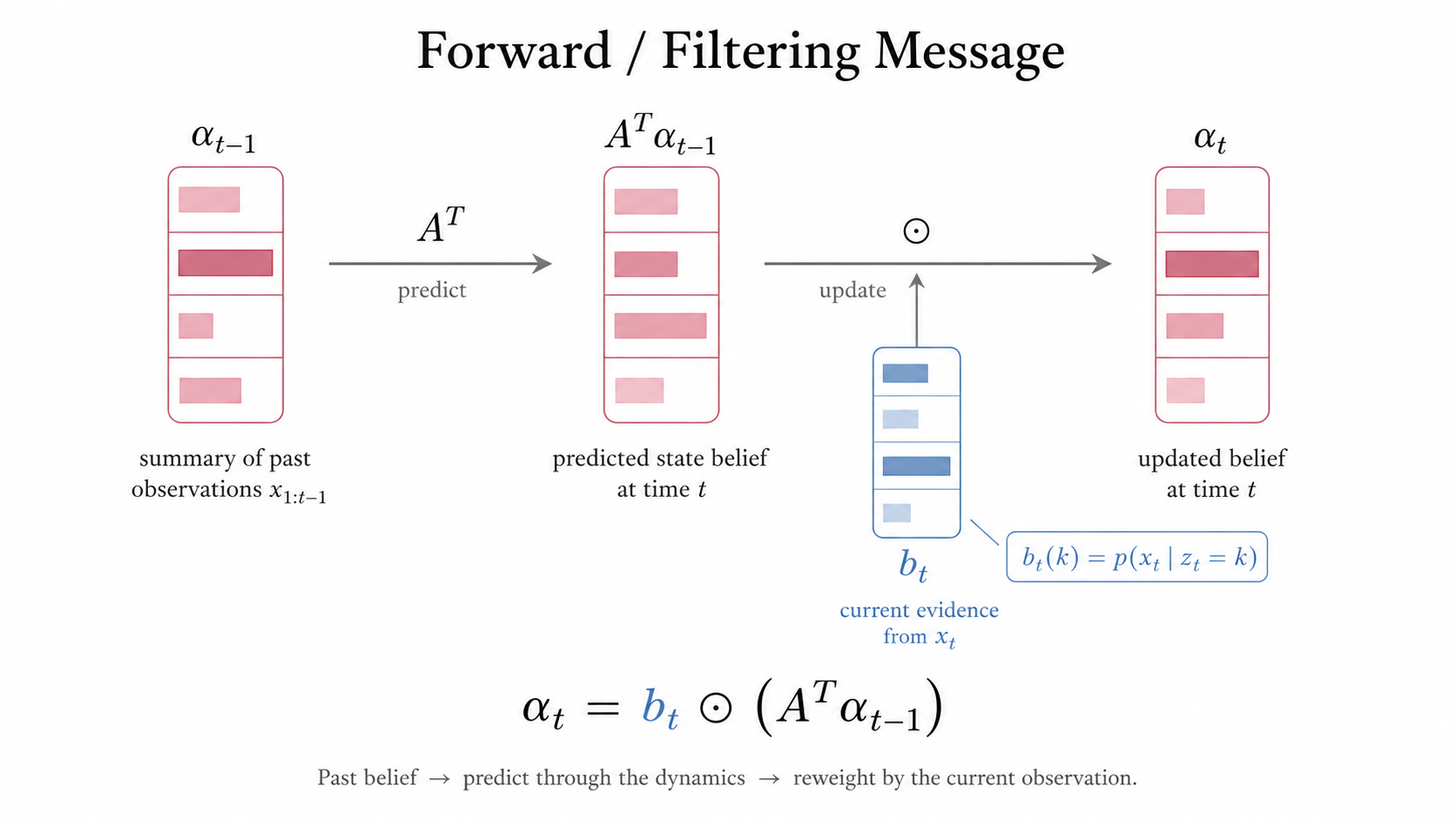
α t ( k ) = p ( x t ∣ z t = k ) ∑ j = 1 K p ( z t = k ∣ z t − 1 = j ) α t − 1 ( j ) \alpha_t(k) = p(x_t \mid z_t = k) \sum_{j=1}^{K} p(z_t = k \mid z_{t-1} = j)\, \alpha_{t-1}(j) α t ( k ) = p ( x t ∣ z t = k ) j = 1 ∑ K p ( z t = k ∣ z t − 1 = j ) α t − 1 ( j ) for t = 1 t = 1 t = 1
α 1 ( k ) = p ( x 1 ∣ z 1 = k ) p ( z 1 = k ) \alpha_1(k) = p(x_1 \mid z_1 = k)\, p(z_1 = k) α 1 ( k ) = p ( x 1 ∣ z 1 = k ) p ( z 1 = k ) The marginal likelihood (probability of the data) p ( x 1 : t ) p(x_{1:t}) p ( x 1 : t ) α \alpha α
p ( x 1 : t ) = ∑ i = 1 K p ( x 1 : t , z t = i ) = ∑ i = 1 K α t ( i ) (3) p(x_{1:t}) = \sum_{i=1}^{K} p(x_{1:t}, z_{t}=i) = \sum_{i=1}^{K} \alpha_{t}(i) \tag{3} p ( x 1 : t ) = i = 1 ∑ K p ( x 1 : t , z t = i ) = i = 1 ∑ K α t ( i ) ( 3 ) Which gives us
p ( z t = k ∣ x 1 : t ) = p ( x t ∣ z t = k ) ∑ j = 1 K p ( z t = k ∣ z t − 1 = j ) α t − 1 ( j ) ∑ i = 1 K α t ( i ) (4) p(z_{t}=k \mid x_{1:t}) = \frac{p(x_{t} \mid z_{t}=k) \displaystyle\sum_{j=1}^{K} p(z_{t}=k \mid z_{t-1}=j)\, \alpha_{t-1}(j)}{\displaystyle\sum_{i=1}^{K} \alpha_{t}(i)} \tag{4} p ( z t = k ∣ x 1 : t ) = i = 1 ∑ K α t ( i ) p ( x t ∣ z t = k ) j = 1 ∑ K p ( z t = k ∣ z t − 1 = j ) α t − 1 ( j ) ( 4 )
Figure 2: Forward filtering message. Filtering alternates between prediction through the transition model and correction by the current observation.
In the context of HMMs, smoothing refers to finding p ( z t ∣ x 1 : T ) p(z_{t} \mid x_{1:T}) p ( z t ∣ x 1 : T ) full observation sequence to infer an intermediate latent state. Intuitively, even observations beyond z t z_t z t z t z_t z t
p ( z t = i ∣ x 1 : T ) = p ( x 1 : T , z t = i ) p ( x 1 : T ) (5) p(z_{t} = i \mid x_{1:T}) = \frac{p(x_{1:T}, z_{t}=i)}{p(x_{1:T})} \tag{5} p ( z t = i ∣ x 1 : T ) = p ( x 1 : T ) p ( x 1 : T , z t = i ) ( 5 ) Focusing on the numerator:
p ( x 1 : T , z t = i ) = p ( x 1 : t , z t = i , x t + 1 : T ) = p ( x 1 : t , z t = i ) p ( x t + 1 : T ∣ z t = i ) \begin{align*}
p(x_{1:T}, z_{t}=i) &= p(x_{1:t}, z_{t}=i, x_{t+1:T}) \\
&= p(x_{1:t}, z_{t}=i)\, p(x_{t+1:T} \mid z_{t}=i)
\end{align*} p ( x 1 : T , z t = i ) = p ( x 1 : t , z t = i , x t + 1 : T ) = p ( x 1 : t , z t = i ) p ( x t + 1 : T ∣ z t = i ) which is using the conditional independence due to the HMM graph, x 1 : t ⊥ x t + 1 : T ∣ z t x_{1:t} \perp x_{t+1:T} \mid z_{t} x 1 : t ⊥ x t + 1 : T ∣ z t
= α t ( i ) p ( x t + 1 : T ∣ z t = i ) = \alpha_{t}(i)\, p(x_{t+1:T} \mid z_{t}=i) = α t ( i ) p ( x t + 1 : T ∣ z t = i )
Definition (Backward variable). Define β t ( i ) ≡ p ( x t + 1 : T ∣ z t = i ) \beta_t(i) \equiv p(x_{t+1:T} \mid z_t = i) β t ( i ) ≡ p ( x t + 1 : T ∣ z t = i )
Proposition (Backward recursion). For 1 ≤ t ≤ T − 1 1 \leq t \leq T-1 1 ≤ t ≤ T − 1
β t ( i ) = ∑ j = 1 K p ( x t + 1 ∣ z t + 1 = j ) A i j β t + 1 ( j ) \beta_t(i) = \sum_{j=1}^{K} p(x_{t+1} \mid z_{t+1}=j)\, A_{ij}\, \beta_{t+1}(j) β t ( i ) = j = 1 ∑ K p ( x t + 1 ∣ z t + 1 = j ) A ij β t + 1 ( j ) with terminal condition β T ( i ) = 1 \beta_T(i) = 1 β T ( i ) = 1
Proof.
β t ( i ) = p ( x t + 1 : T ∣ z t = i ) = ∑ j = 1 K p ( x t + 1 : T , z t + 1 = j ∣ z t = i ) = ∑ j = 1 K p ( x t + 1 , x t + 2 : T , z t + 1 = j ∣ z t = i ) = ∑ j = 1 K p ( x t + 1 , x t + 2 : T ∣ z t + 1 = j , z t = i ) p ( z t + 1 = j ∣ z t = i ) \begin{align*}
\beta_t(i) &= p(x_{t+1:T} \mid z_{t}=i) = \sum_{j=1}^{K} p(x_{t+1:T}, z_{t+1}=j \mid z_{t}=i) \\
&= \sum_{j=1}^{K} p(x_{t+1}, x_{t+2:T}, z_{t+1}=j \mid z_{t}=i) \\
&= \sum_{j=1}^{K} p(x_{t+1}, x_{t+2:T} \mid z_{t+1}=j, z_{t}=i)\, p(z_{t+1}=j \mid z_{t}=i)
\end{align*} β t ( i ) = p ( x t + 1 : T ∣ z t = i ) = j = 1 ∑ K p ( x t + 1 : T , z t + 1 = j ∣ z t = i ) = j = 1 ∑ K p ( x t + 1 , x t + 2 : T , z t + 1 = j ∣ z t = i ) = j = 1 ∑ K p ( x t + 1 , x t + 2 : T ∣ z t + 1 = j , z t = i ) p ( z t + 1 = j ∣ z t = i ) and now because x t + 2 : T ⊥ ( x t + 1 , z t ) ∣ z t + 1 x_{t+2:T} \perp (x_{t+1}, z_{t}) \mid z_{t+1} x t + 2 : T ⊥ ( x t + 1 , z t ) ∣ z t + 1 x t + 1 ⊥ z t ∣ z t + 1 x_{t+1} \perp z_t \mid z_{t+1} x t + 1 ⊥ z t ∣ z t + 1
= ∑ j = 1 K p ( x t + 1 ∣ z t + 1 = j ) p ( x t + 2 : T ∣ z t + 1 = j ) ⏟ β t + 1 ( j ) p ( z t + 1 = j ∣ z t = i ) ⏟ A i j = ∑ j = 1 K p ( x t + 1 ∣ z t + 1 = j ) A i j β t + 1 ( j ) \begin{align*}
&= \sum_{j=1}^{K} p(x_{t+1} \mid z_{t+1}=j)\, \underbrace{p(x_{t+2:T} \mid z_{t+1}=j)}_{\beta_{t+1}(j)}\, \underbrace{p(z_{t+1}=j \mid z_{t}=i)}_{A_{ij}} \\
&= \sum_{j=1}^{K} p(x_{t+1} \mid z_{t+1}=j)\, A_{ij}\, \beta_{t+1}(j)
\end{align*} = j = 1 ∑ K p ( x t + 1 ∣ z t + 1 = j ) β t + 1 ( j ) p ( x t + 2 : T ∣ z t + 1 = j ) A ij p ( z t + 1 = j ∣ z t = i ) = j = 1 ∑ K p ( x t + 1 ∣ z t + 1 = j ) A ij β t + 1 ( j ) and for t = T t=T t = T β T ( j ) = 1 \beta_{T}(j) = 1 β T ( j ) = 1 j ∈ { 1 , … , K } j \in \{1, \ldots, K\} j ∈ { 1 , … , K } □ \square □
Definition (Smoother). Define γ t ( i ) ≡ p ( z t = i ∣ x 1 : T ) \gamma_{t}(i) \equiv p(z_{t}=i \mid x_{1:T}) γ t ( i ) ≡ p ( z t = i ∣ x 1 : T )
Proposition (Smoothing distribution). Putting together (5), for any t t t
γ t ( i ) = p ( z t = i ∣ x 1 : T ) = α t ( i ) β t ( i ) ∑ j = 1 K α t ( j ) β t ( j ) \gamma_t(i) = p(z_t=i \mid x_{1:T}) = \frac{\alpha_t(i)\,\beta_t(i)}{\sum_{j=1}^{K} \alpha_t(j)\,\beta_t(j)} γ t ( i ) = p ( z t = i ∣ x 1 : T ) = ∑ j = 1 K α t ( j ) β t ( j ) α t ( i ) β t ( i ) Parameter Fitting The model parameters consist of the initial state distribution, the transition distribution between latent states, and the emission distribution associated with each latent state.
That is, the model parameters are:
π k = p ( z 1 = k ) , A j k = p ( z t = k ∣ z t − 1 = j ) , B k = emission parameters for state k \pi_k = p(z_1 = k), \qquad A_{jk} = p(z_t = k \mid z_{t-1} = j), \qquad B_k = \text{emission parameters for state } k π k = p ( z 1 = k ) , A j k = p ( z t = k ∣ z t − 1 = j ) , B k = emission parameters for state k Following the method of maximum likelihood estimation, we'd like to maximize the probability of the data given the parameters.
θ ^ = argmax θ ∈ Θ log p ( X ∣ θ ) = argmax θ ∈ Θ log ( ∏ n = 1 N p ( x n ∣ θ ) ) = argmax θ ∈ Θ log ( ∏ n = 1 N ∑ z n p ( x n , z n ∣ θ ) ) = argmax θ ∈ Θ ∑ n = 1 N log ∑ z n p ( x n , z n ∣ θ ) \begin{align*}
\hat{\boldsymbol{\theta}} &= \operatorname*{argmax}_{\theta \in \Theta}\ \log p(\mathbf{X} \mid \boldsymbol{\theta}) \\
&= \operatorname*{argmax}_{\theta \in \Theta}\ \log \left( \prod_{n=1}^{N} p(\mathbf{x}_{n} \mid \boldsymbol{\theta}) \right) \\
&= \operatorname*{argmax}_{\theta \in \Theta}\ \log \left( \prod_{n=1}^{N} \sum_{\mathbf{z}_n} p(\mathbf{x}_{n}, \mathbf{z}_{n} \mid \boldsymbol{\theta}) \right) \\
&= \operatorname*{argmax}_{\theta \in \Theta} \sum_{n=1}^{N} \log \sum_{\mathbf{z}_n} p(\mathbf{x}_{n}, \mathbf{z}_{n} \mid \boldsymbol{\theta})
\end{align*} θ ^ = θ ∈ Θ argmax log p ( X ∣ θ ) = θ ∈ Θ argmax log ( n = 1 ∏ N p ( x n ∣ θ ) ) = θ ∈ Θ argmax log ( n = 1 ∏ N z n ∑ p ( x n , z n ∣ θ ) ) = θ ∈ Θ argmax n = 1 ∑ N log z n ∑ p ( x n , z n ∣ θ ) The sum over latent sequences appears inside the logarithm, which couples the parameters across all possible z n \mathbf{z}_n z n
Expectation-Maximization - E-step Under EM we want to maximize the expected complete-data log-likelihood under the current posterior:
Q ( θ , θ old ) = E p ( z 1 : T ∣ x 1 : T , θ old ) [ log p ( x 1 : T , z 1 : T ∣ θ ) ] = E p ( z 1 : T ∣ x 1 : T , θ old ) [ ∑ k = 1 K I ( z 1 = k ) log π k + ∑ t = 2 T ∑ j = 1 K ∑ k = 1 K I ( z t − 1 = j , z t = k ) log A j k + ∑ t = 1 T ∑ k = 1 K I ( z t = k ) log p ( x t ∣ z t = k ; B k ) ] \begin{align*}
Q(\theta, \theta^{\text{old}})
&= \mathbb{E}_{p(z_{1:T} \mid x_{1:T}, \theta^{\text{old}})} \left[ \log p(x_{1:T}, z_{1:T} \mid \theta) \right] \\
&= \mathbb{E}_{p(z_{1:T} \mid x_{1:T}, \theta^{\text{old}})} \Biggl[
\sum_{k=1}^{K} \mathbb{I}(z_{1}=k) \log \pi_{k} \\
&\qquad\qquad + \sum_{t=2}^{T} \sum_{j=1}^{K} \sum_{k=1}^{K} \mathbb{I}(z_{t-1}=j, z_{t}=k) \log A_{jk} \\
&\qquad\qquad + \sum_{t=1}^{T} \sum_{k=1}^{K} \mathbb{I}(z_{t}=k) \log p(x_{t} \mid z_{t}=k; B_{k})
\Biggr]
\end{align*} Q ( θ , θ old ) = E p ( z 1 : T ∣ x 1 : T , θ old ) [ log p ( x 1 : T , z 1 : T ∣ θ ) ] = E p ( z 1 : T ∣ x 1 : T , θ old ) [ k = 1 ∑ K I ( z 1 = k ) log π k + t = 2 ∑ T j = 1 ∑ K k = 1 ∑ K I ( z t − 1 = j , z t = k ) log A j k + t = 1 ∑ T k = 1 ∑ K I ( z t = k ) log p ( x t ∣ z t = k ; B k ) ] Moving expectations inside:
= ∑ k = 1 K p ( z 1 = k ∣ x 1 : T ) log π k + ∑ t = 2 T ∑ j = 1 K ∑ k = 1 K p ( z t − 1 = j , z t = k ∣ x 1 : T ) log A j k + ∑ t = 1 T ∑ k = 1 K p ( z t = k ∣ x 1 : T ) log p ( x t ∣ z t = k ; B k ) = ∑ k = 1 K γ 1 ( k ) log π k + ∑ t = 2 T ∑ j = 1 K ∑ k = 1 K ξ t ( j , k ) ⏟ p ( z t − 1 = j , z t = k ∣ x 1 : T ) log A j k + ∑ t = 1 T ∑ k = 1 K γ t ( k ) log p ( x t ∣ z t = k ; B k ) \begin{align*}
&= \sum_{k=1}^{K} p(z_{1}=k \mid x_{1:T}) \log \pi_{k} \\
&\qquad + \sum_{t=2}^{T} \sum_{j=1}^{K} \sum_{k=1}^{K} p(z_{t-1}=j, z_{t}=k \mid x_{1:T}) \log A_{jk} \\
&\qquad + \sum_{t=1}^{T} \sum_{k=1}^{K} p(z_{t}=k \mid x_{1:T}) \log p(x_{t} \mid z_{t}=k; B_{k}) \\[6pt]
&= \sum_{k=1}^{K} \gamma_{1}(k) \log \pi_{k} \\
&\qquad + \sum_{t=2}^{T} \sum_{j=1}^{K} \sum_{k=1}^{K} \underbrace{\xi_{t}(j,k)}_{p(z_{t-1}=j,\, z_t=k \mid x_{1:T})} \log A_{jk} \\
&\qquad + \sum_{t=1}^{T} \sum_{k=1}^{K} \gamma_{t}(k) \log p(x_{t} \mid z_{t}=k; B_{k})
\end{align*} = k = 1 ∑ K p ( z 1 = k ∣ x 1 : T ) log π k + t = 2 ∑ T j = 1 ∑ K k = 1 ∑ K p ( z t − 1 = j , z t = k ∣ x 1 : T ) log A j k + t = 1 ∑ T k = 1 ∑ K p ( z t = k ∣ x 1 : T ) log p ( x t ∣ z t = k ; B k ) = k = 1 ∑ K γ 1 ( k ) log π k + t = 2 ∑ T j = 1 ∑ K k = 1 ∑ K p ( z t − 1 = j , z t = k ∣ x 1 : T ) ξ t ( j , k ) log A j k + t = 1 ∑ T k = 1 ∑ K γ t ( k ) log p ( x t ∣ z t = k ; B k )
Definition (Pairwise Smoother). Define ξ t ( j , k ) ≡ p ( z t − 1 = j , z t = k ∣ x 1 : T ) \xi_{t}(j,k) \equiv p(z_{t-1}=j,\, z_t=k \mid x_{1:T}) ξ t ( j , k ) ≡ p ( z t − 1 = j , z t = k ∣ x 1 : T )
Writing ξ t ( j , k ) \xi_{t}(j,k) ξ t ( j , k )
ξ t ( j , k ) = p ( z t − 1 = j , z t = k ∣ x 1 : T ) = p ( z t − 1 = j , z t = k , x 1 : T ) p ( x 1 : T ) = p ( z t − 1 = j , z t = k , x 1 : t − 1 , x t , x t + 1 : T ) p ( x 1 : T ) = p ( x 1 : t − 1 , z t − 1 = j ) p ( z t = k ∣ z t − 1 = j ) p ( x t ∣ z t = k ) p ( x t + 1 : T ∣ z t = k ) p ( x 1 : T ) = α t − 1 ( j ) A j k p ( x t ∣ z t = k ) β t ( k ) ∑ i = 1 K α t ( i ) β t ( i ) \begin{align*}
\xi_{t}(j,k) &= p(z_{t-1}=j, z_{t}=k \mid x_{1:T}) \\
&= \frac{p(z_{t-1}=j, z_{t}=k, x_{1:T})}{p(x_{1:T})} \\
&= \frac{p(z_{t-1}=j, z_{t}=k, x_{1:t-1}, x_{t}, x_{t+1:T})}{p(x_{1:T})} \\
&= \frac{p(x_{1:t-1}, z_{t-1}=j)\, p(z_{t}=k \mid z_{t-1}=j)\, p(x_{t} \mid z_{t}=k)\, p(x_{t+1:T} \mid z_{t}=k)}{p(x_{1:T})} \\
&= \frac{\alpha_{t-1}(j)\, A_{jk}\, p(x_{t} \mid z_{t}=k)\, \beta_{t}(k)}{\sum_{i=1}^{K} \alpha_{t}(i)\, \beta_{t}(i)}
\end{align*} ξ t ( j , k ) = p ( z t − 1 = j , z t = k ∣ x 1 : T ) = p ( x 1 : T ) p ( z t − 1 = j , z t = k , x 1 : T ) = p ( x 1 : T ) p ( z t − 1 = j , z t = k , x 1 : t − 1 , x t , x t + 1 : T ) = p ( x 1 : T ) p ( x 1 : t − 1 , z t − 1 = j ) p ( z t = k ∣ z t − 1 = j ) p ( x t ∣ z t = k ) p ( x t + 1 : T ∣ z t = k ) = ∑ i = 1 K α t ( i ) β t ( i ) α t − 1 ( j ) A j k p ( x t ∣ z t = k ) β t ( k ) To summarize:
Q ( θ , θ old ) = ∑ k γ 1 ( k ) log π k ⏟ Q π + ∑ t = 2 T ∑ j , k ξ t ( j , k ) log A j k ⏟ Q A + ∑ t = 1 T ∑ k γ t ( k ) log p ( x t ∣ z t = k ; B k ) ⏟ Q B Q(\theta, \theta^{\text{old}}) = \underbrace{\sum_{k} \gamma_1(k) \log \pi_k}_{Q_{\pi}} + \underbrace{\sum_{t=2}^{T} \sum_{j,k} \xi_t(j,k) \log A_{jk}}_{Q_{A}} + \underbrace{\sum_{t=1}^{T} \sum_{k} \gamma_t(k) \log p(x_t \mid z_t=k; B_k)}_{Q_{B}} Q ( θ , θ old ) = Q π k ∑ γ 1 ( k ) log π k + Q A t = 2 ∑ T j , k ∑ ξ t ( j , k ) log A j k + Q B t = 1 ∑ T k ∑ γ t ( k ) log p ( x t ∣ z t = k ; B k ) We have now computed the expectation of the log-likelihood under the posterior of the latent variables.
Expectation Maximization - M-step Now, we need to update the parameters of our model θ = ( π , A , B ) \theta = (\pi, A, B) θ = ( π , A , B ) Q Q Q Q π Q_{\pi} Q π
Initial distribution.
Q π = ∑ k γ 1 ( k ) log π k subject to ∑ k π k = 1 Q_{\pi} = \sum_{k} \gamma_1(k) \log \pi_k \quad \text{subject to } \sum_{k} \pi_{k} = 1 Q π = k ∑ γ 1 ( k ) log π k subject to k ∑ π k = 1 Setting up the Lagrangian:
L ( π , λ ) = ∑ k = 1 K γ 1 ( k ) log π k + λ ( ∑ k = 1 K π k − 1 ) ∂ L ∂ π k = γ 1 ( k ) π k + λ = 0 π k = − γ 1 ( k ) λ \begin{align*}
\mathcal{L}(\pi, \lambda) &= \sum_{k=1}^{K} \gamma_{1}(k) \log \pi_{k} + \lambda \left( \sum_{k=1}^{K} \pi_{k} - 1 \right) \\
\frac{\partial \mathcal{L}}{\partial \pi_{k}} &= \frac{\gamma_{1}(k)}{\pi_{k}} + \lambda = 0 \\
\pi_{k} &= \frac{-\gamma_{1}(k)}{\lambda}
\end{align*} L ( π , λ ) ∂ π k ∂ L π k = k = 1 ∑ K γ 1 ( k ) log π k + λ ( k = 1 ∑ K π k − 1 ) = π k γ 1 ( k ) + λ = 0 = λ − γ 1 ( k ) Now using the constraint:
∑ k = 1 K π k = 1 ⟹ ∑ k − γ 1 ( k ) λ = 1 \sum_{k=1}^{K} \pi_{k} = 1 \implies \sum_{k} \frac{-\gamma_{1}(k)}{\lambda} = 1 k = 1 ∑ K π k = 1 ⟹ k ∑ λ − γ 1 ( k ) = 1 and because γ 1 ( k ) ≡ p ( z 1 = k ∣ x 1 : T ) \gamma_{1}(k) \equiv p(z_{1}=k \mid x_{1:T}) γ 1 ( k ) ≡ p ( z 1 = k ∣ x 1 : T ) ∑ k p ( z 1 = k ∣ x 1 : T ) = 1 \sum_{k} p(z_{1}=k \mid x_{1:T}) = 1 ∑ k p ( z 1 = k ∣ x 1 : T ) = 1
λ = − 1 ⟹ π k new = γ 1 ( k ) \lambda = -1 \implies \boxed{\pi_{k}^{\text{new}} = \gamma_{1}(k)} λ = − 1 ⟹ π k new = γ 1 ( k ) Now we take a brief detour to prove a classic result which can be reused.
Lemma. The solution to max p ∑ k w k log p k \max_p \sum_k w_k \log p_k max p ∑ k w k log p k ∑ k p k = 1 \sum_k p_k = 1 ∑ k p k = 1 p k ≥ 0 p_k \geq 0 p k ≥ 0
p k = w k ∑ j w j p_k = \frac{w_k}{\sum_j w_j} p k = ∑ j w j w k Proof. From the Lagrangian L ( p , λ ) = ∑ k w k log p k + λ ( ∑ k p k − 1 ) \mathcal{L}(p, \lambda) = \sum_{k} w_{k} \log p_{k} + \lambda (\sum_{k} p_{k} - 1) L ( p , λ ) = ∑ k w k log p k + λ ( ∑ k p k − 1 ) p k p_{k} p k ∂ L ∂ p k = w k p k + λ = 0 \frac{\partial \mathcal{L}}{\partial p_{k}} = \frac{w_{k}}{p_{k}} + \lambda = 0 ∂ p k ∂ L = p k w k + λ = 0 w k p k = − λ ⟹ p k = w k − λ ⟹ − λ = ∑ k w k \frac{w_{k}}{p_{k}} = -\lambda \implies p_{k} = \frac{w_{k}}{-\lambda} \implies -\lambda = \sum_{k} w_{k} p k w k = − λ ⟹ p k = − λ w k ⟹ − λ = ∑ k w k ∑ k p k = 1 \sum_k p_k = 1 ∑ k p k = 1 p k = w k ∑ j w j p_{k} = \frac{w_{k}}{\sum_{j} w_{j}} p k = ∑ j w j w k □ \square □
Transition matrix. The result applies to Q A Q_{A} Q A
Q A = ∑ t = 2 T ∑ j , k ξ t ( j , k ) log A j k = ∑ j ∑ k ∑ t = 2 T ξ t ( j , k ) log A j k \begin{align*}
Q_{A} &= \sum_{t=2}^{T} \sum_{j,k} \xi_t(j,k) \log A_{jk} \\
&= \sum_{j} \sum_{k} \sum_{t=2}^{T} \xi_t(j,k) \log A_{jk}
\end{align*} Q A = t = 2 ∑ T j , k ∑ ξ t ( j , k ) log A j k = j ∑ k ∑ t = 2 ∑ T ξ t ( j , k ) log A j k Considering a particular j j j
∑ k ∑ t = 2 T ξ t ( j , k ) log A j k s.t. ∑ k = 1 K A j k = 1 \sum_{k} \sum_{t=2}^{T} \xi_t(j,k) \log A_{jk} \quad \text{s.t. } \sum_{k=1}^{K} A_{jk} = 1 k ∑ t = 2 ∑ T ξ t ( j , k ) log A j k s.t. k = 1 ∑ K A j k = 1 Making use of the Lemma, we see this is maximized by
A j k = ∑ t = 2 T ξ t ( j , k ) ∑ i = 1 K ∑ t = 2 T ξ t ( j , i ) A_{jk} = \frac{\sum_{t=2}^{T} \xi_{t}(j,k)}{\sum_{i=1}^{K}\sum_{t=2}^{T} \xi_{t}(j,i)} A j k = ∑ i = 1 K ∑ t = 2 T ξ t ( j , i ) ∑ t = 2 T ξ t ( j , k ) and because
∑ i = 1 K ∑ t = 2 T ξ t ( j , i ) = ∑ t = 2 T ∑ i = 1 K ξ t ( j , i ) = ∑ t = 2 T ∑ i = 1 K p ( z t = i , z t − 1 = j ∣ x 1 : T ) = ∑ t = 2 T p ( z t − 1 = j ∣ x 1 : T ) = ∑ t = 2 T γ t − 1 ( j ) \begin{align*}
\sum_{i=1}^{K}\sum_{t=2}^{T} \xi_{t}(j,i) &= \sum_{t=2}^{T} \sum_{i=1}^{K} \xi_{t}(j,i) \\
&= \sum_{t=2}^{T} \sum_{i=1}^{K} p(z_{t}=i, z_{t-1}=j \mid x_{1:T}) \\
&= \sum_{t=2}^{T} p(z_{t-1}=j \mid x_{1:T}) \\
&= \sum_{t=2}^{T} \gamma_{t-1}(j)
\end{align*} i = 1 ∑ K t = 2 ∑ T ξ t ( j , i ) = t = 2 ∑ T i = 1 ∑ K ξ t ( j , i ) = t = 2 ∑ T i = 1 ∑ K p ( z t = i , z t − 1 = j ∣ x 1 : T ) = t = 2 ∑ T p ( z t − 1 = j ∣ x 1 : T ) = t = 2 ∑ T γ t − 1 ( j ) Therefore, substituting this result into the denominator:
A j k new = ∑ t = 2 T ξ t ( j , k ) ∑ t = 2 T γ t − 1 ( j ) (6) \boxed{A_{jk}^{\text{new}} = \frac{\sum_{t=2}^{T} \xi_{t}(j,k)}{\sum_{t=2}^{T} \gamma_{t-1}(j)}} \tag{6} A j k new = ∑ t = 2 T γ t − 1 ( j ) ∑ t = 2 T ξ t ( j , k ) ( 6 )
Remark. The updated transition parameters become the normalized estimated/"soft" (from the E-step) counts of transitions from j → k j \to k j → k
The final term to deal with is the emission parameters. The optimization depends on whether we choose emission to be categorical, Gaussian, or some other distribution. For a categorical distribution, we can follow a similar approach using the general result as we did with Q A Q_{A} Q A Q π Q_{\pi} Q π
Let us also show the derivation for Gaussian emissions.
Emission parameters (Gaussian).
Q B = ∑ t = 1 T ∑ k γ t ( k ) log p ( x t ∣ z t = k ; B k ) = ∑ t = 1 T ∑ k γ t ( k ) [ − ( x t − μ k ) 2 2 σ k 2 − log ( σ k 2 π ) ] = ∑ k ∑ t = 1 T γ t ( k ) [ − ( x t − μ k ) 2 2 σ k 2 − log ( σ k 2 π ) ] \begin{align*}
Q_{B} &= \sum_{t=1}^{T} \sum_{k} \gamma_{t}(k) \log p(x_{t} \mid z_{t}=k; B_{k}) \\
&= \sum_{t=1}^{T} \sum_{k} \gamma_{t}(k)
\left[
-\frac{(x_t - \mu_k)^2}{2\sigma_k^2}
- \log\left(\sigma_k \sqrt{2\pi}\right)
\right] \\
&= \sum_{k} \sum_{t=1}^{T} \gamma_{t}(k)
\left[
-\frac{(x_t - \mu_k)^2}{2\sigma_k^2}
- \log\left(\sigma_k \sqrt{2\pi}\right)
\right]
\end{align*} Q B = t = 1 ∑ T k ∑ γ t ( k ) log p ( x t ∣ z t = k ; B k ) = t = 1 ∑ T k ∑ γ t ( k ) [ − 2 σ k 2 ( x t − μ k ) 2 − log ( σ k 2 π ) ] = k ∑ t = 1 ∑ T γ t ( k ) [ − 2 σ k 2 ( x t − μ k ) 2 − log ( σ k 2 π ) ] Let's start by finding μ k \mu_{k} μ k
∂ Q B ∂ μ k = ∑ t = 1 T γ t ( k ) [ x t − μ k σ k 2 ] = 0 ⟹ ∑ t = 1 T γ t ( k ) ( x t − μ k ) = 0 ⟹ μ k new = ∑ t = 1 T γ t ( k ) x t ∑ t = 1 T γ t ( k ) \begin{align*}
\frac{\partial Q_{B}}{\partial \mu_{k}} &= \sum_{t=1}^{T} \gamma_{t}(k) \left[ \frac{x_{t} - \mu_{k}}{\sigma_{k}^{2}} \right] = 0 \\
&\implies \sum_{t=1}^{T} \gamma_{t}(k) \left( x_{t} - \mu_{k}\right) = 0 \\
&\implies \boxed{\mu_{k}^{\text{new}} = \frac{\sum_{t=1}^{T} \gamma_{t}(k) x_{t}}{\sum_{t=1}^{T} \gamma_{t}(k)}} \tag{7}
\end{align*} ∂ μ k ∂ Q B = t = 1 ∑ T γ t ( k ) [ σ k 2 x t − μ k ] = 0 ⟹ t = 1 ∑ T γ t ( k ) ( x t − μ k ) = 0 ⟹ μ k new = ∑ t = 1 T γ t ( k ) ∑ t = 1 T γ t ( k ) x t ( 7 ) Now, solving for the variance term:
∂ Q B ∂ σ k = ∑ t = 1 T γ t ( k ) [ ( x t − μ k ) 2 σ k 3 − 1 σ k ] = 0 ⟹ σ k 2 ∑ t = 1 T γ t ( k ) = ∑ t = 1 T γ t ( k ) ( x t − μ k ) 2 ⟹ ( σ k 2 ) new = ∑ t = 1 T γ t ( k ) ( x t − μ k new ) 2 ∑ t = 1 T γ t ( k ) \begin{align*}
\frac{\partial Q_{B}}{\partial \sigma_{k}} &= \sum_{t=1}^{T} \gamma_{t}(k) \left[ \frac{(x_{t} - \mu_{k})^{2}}{\sigma_{k}^{3}} - \frac{1}{\sigma_{k}}\right] = 0 \\
&\implies \sigma_{k}^{2} \sum_{t=1}^{T} \gamma_{t}(k) = \sum_{t=1}^{T} \gamma_{t}(k) (x_{t} - \mu_{k})^{2} \\
&\implies \boxed{(\sigma_{k}^{2})^{\text{new}} = \frac{\sum_{t=1}^{T} \gamma_{t}(k) (x_{t} - \mu_{k}^{\text{new}})^{2}}{\sum_{t=1}^{T} \gamma_{t}(k)}} \tag{8}
\end{align*} ∂ σ k ∂ Q B = t = 1 ∑ T γ t ( k ) [ σ k 3 ( x t − μ k ) 2 − σ k 1 ] = 0 ⟹ σ k 2 t = 1 ∑ T γ t ( k ) = t = 1 ∑ T γ t ( k ) ( x t − μ k ) 2 ⟹ ( σ k 2 ) new = ∑ t = 1 T γ t ( k ) ∑ t = 1 T γ t ( k ) ( x t − μ k new ) 2 ( 8 ) The updates (7) and (8) are the standard Gaussian MLE estimates, except each observation is weighted by the posterior probability that it was generated by state k k k
EM Algorithm Summary (Vectorized) Given current parameters θ old = ( π , A , B ) \theta^{\text{old}} = (\pi, A, B) θ old = ( π , A , B )
b t = [ p ( x t ∣ z t = 1 ; B 1 ) ⋮ p ( x t ∣ z t = K ; B K ) ] \mathbf{b}_t =
\begin{bmatrix}
p(x_t \mid z_t=1; B_1) \\
\vdots \\
p(x_t \mid z_t=K; B_K)
\end{bmatrix} b t = p ( x t ∣ z t = 1 ; B 1 ) ⋮ p ( x t ∣ z t = K ; B K ) Let ⊙ \odot ⊙
E-step. Compute the forward vectors α t \bm{\alpha}_t α t β t \bm{\beta}_t β t
α 1 = b 1 ⊙ π , α t = b t ⊙ ( A ⊤ α t − 1 ) , t = 2 , … , T (9) \bm{\alpha}_1 = \mathbf{b}_1 \odot \bm{\pi}, \qquad
\bm{\alpha}_t = \mathbf{b}_t \odot \left(\mathbf{A}^{\top} \bm{\alpha}_{t-1}\right), \quad t=2,\dots,T \tag{9} α 1 = b 1 ⊙ π , α t = b t ⊙ ( A ⊤ α t − 1 ) , t = 2 , … , T ( 9 ) and
β T = 1 , β t = A ( b t + 1 ⊙ β t + 1 ) , t = T − 1 , … , 1 \bm{\beta}_T = \mathbf{1}, \qquad
\bm{\beta}_t = \mathbf{A}\left(\mathbf{b}_{t+1} \odot \bm{\beta}_{t+1}\right), \quad t=T-1,\dots,1 β T = 1 , β t = A ( b t + 1 ⊙ β t + 1 ) , t = T − 1 , … , 1 Then compute the smoothing probabilities
γ t = α t ⊙ β t α t ⊤ β t \bm{\gamma}_t = \frac{\bm{\alpha}_t \odot \bm{\beta}_t}{\bm{\alpha}_t^{\top} \bm{\beta}_t} γ t = α t ⊤ β t α t ⊙ β t For t = 2 , … , T t=2,\dots,T t = 2 , … , T
Ξ t = diag ( α t − 1 ) A diag ( b t ⊙ β t ) α t ⊤ β t ∈ R K × K \bm{\Xi}_t =
\frac{
\operatorname{diag}(\bm{\alpha}_{t-1})\,
\mathbf{A}\,
\operatorname{diag}(\mathbf{b}_t \odot \bm{\beta}_t)
}
{
\bm{\alpha}_t^{\top}\bm{\beta}_t
} \in \mathbb{R}^{K \times K} Ξ t = α t ⊤ β t diag ( α t − 1 ) A diag ( b t ⊙ β t ) ∈ R K × K where ( Ξ t ) j k = ξ t ( j , k ) (\bm{\Xi}_t)_{jk} = \xi_t(j,k) ( Ξ t ) j k = ξ t ( j , k )
M-step. Update the parameters:
π new = γ 1 \bm{\pi}^{\text{new}} = \bm{\gamma}_1 π new = γ 1 Then define the expected transition count matrix N = ∑ t = 2 T Ξ t \mathbf{N} = \sum_{t=2}^{T} \bm{\Xi}_t N = ∑ t = 2 T Ξ t j j j j j j
A new = row-normalize ( ∑ t = 2 T Ξ t ) \mathbf{A}^{\text{new}} = \text{row-normalize}\!\left(\sum_{t=2}^{T} \bm{\Xi}_t\right) A new = row-normalize ( t = 2 ∑ T Ξ t ) Then for the Gaussian parameters, defining x ∈ R T \mathbf{x} \in \mathbb{R}^{T} x ∈ R T Γ ∈ R T × K \Gamma \in \mathbb{R}^{T \times K} Γ ∈ R T × K γ t \bm{\gamma}_t γ t
μ new = Γ ⊤ x Γ ⊤ 1 \bm{\mu}^{\text{new}} = \frac{\Gamma^\top \mathbf{x}}{\Gamma^\top \mathbf{1}} μ new = Γ ⊤ 1 Γ ⊤ x Define a residual matrix R ∈ R T × K \mathbf{R} \in \mathbb{R}^{T \times K} R ∈ R T × K
R t k = x t − μ k new R_{tk} = x_t - \mu_k^{\text{new}} R t k = x t − μ k new Then the variance update is
( σ 2 ) new = ( Γ ⊙ R ⊙ 2 ) ⊤ 1 Γ ⊤ 1 (\bm{\sigma}^{2})^{\text{new}} = \frac{(\Gamma \odot \mathbf{R}^{\odot 2})^\top \mathbf{1}}{\Gamma^\top \mathbf{1}} ( σ 2 ) new = Γ ⊤ 1 ( Γ ⊙ R ⊙ 2 ) ⊤ 1 where R ⊙ 2 \mathbf{R}^{\odot 2} R ⊙ 2